High-quality data annotation is the foundation of every successful AI model. This guide explains what data annotation is, the main types (text, image, video, and audio), and how to ensure accuracy, consistency, and scalability in your AI training data.


AI models are only as smart as the data they learn from. If you’re trying to create an AI model that recognizes patterns, makes decisions, and generates insights, then your training data needs to include good examples. In other words, you need data annotation.
There are several kinds of AI data annotation depending on what the task requires. If developers design an AI model to analyze audio recordings, transcribers must prepare accurate text versions. Likewise, if the AI interprets sensor readings, the preparer must understand time-series data.
Quality is also critical, a paragraph from an expert will help a model make better choices compared to a sentence from a layperson. Organizations need to invest in the correct type and quality level of data annotation so that an AI model works the way it’s supposed to across millions of customer interactions.
This comprehensive guide will walk you through everything you need to know about data annotation.
Here’s what you can expect:
AI data annotation is the process of preparing raw information for ingestion into an LLM by labeling it with metadata, allowing it to distinguish between images, generate text and speech, optimize business processes, and navigate in the real world.
Not all data annotation is the same. People often use data labeling and data tagging interchangeably to describe taking a piece of data and sorting it into a category. For example, this could mean taking a sentence like “Mrs. Dalloway said she would buy the flowers herself” and categorizing each element within it:

We call this process Named Entity Recognition (NER) tagging. Each important element within a piece of text becomes tagged and labeled with its meaning.
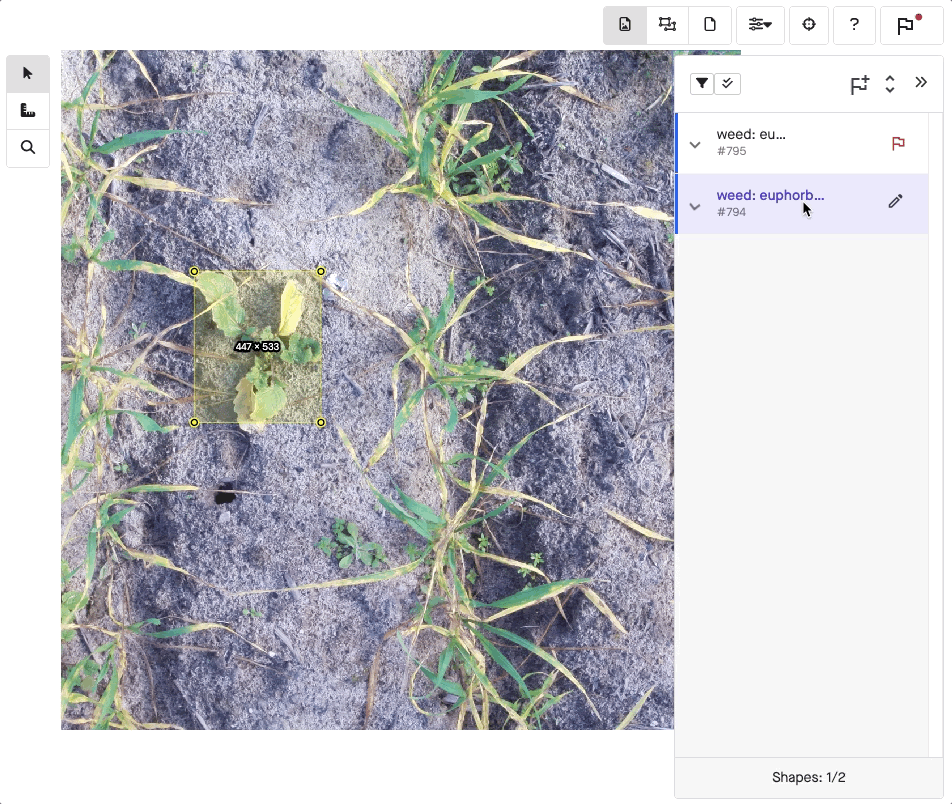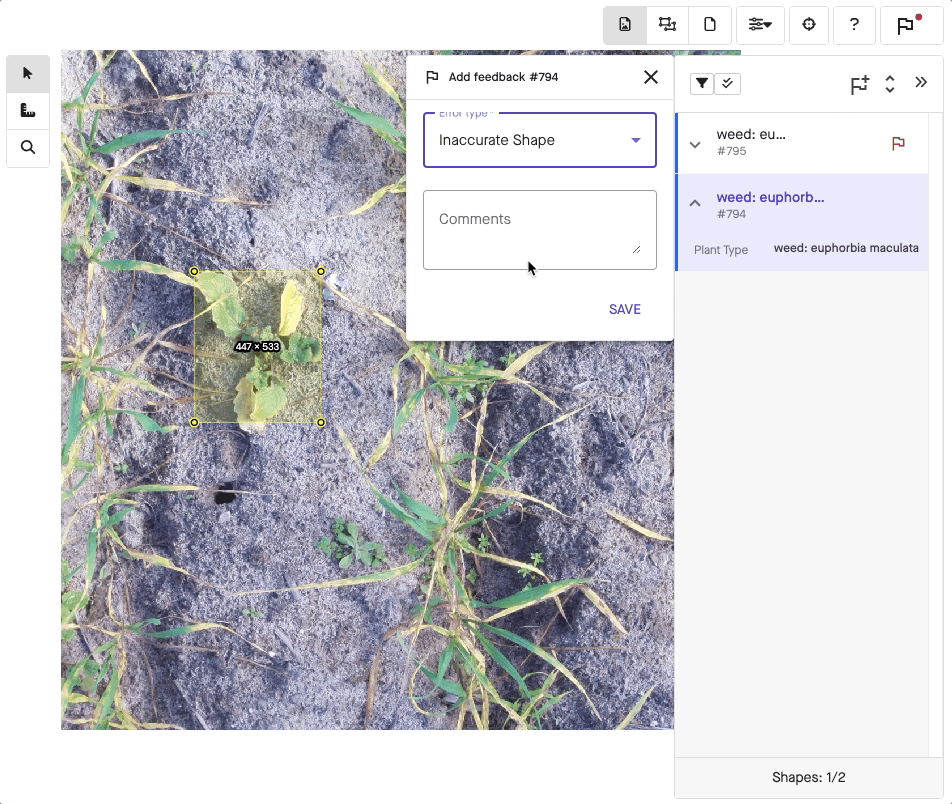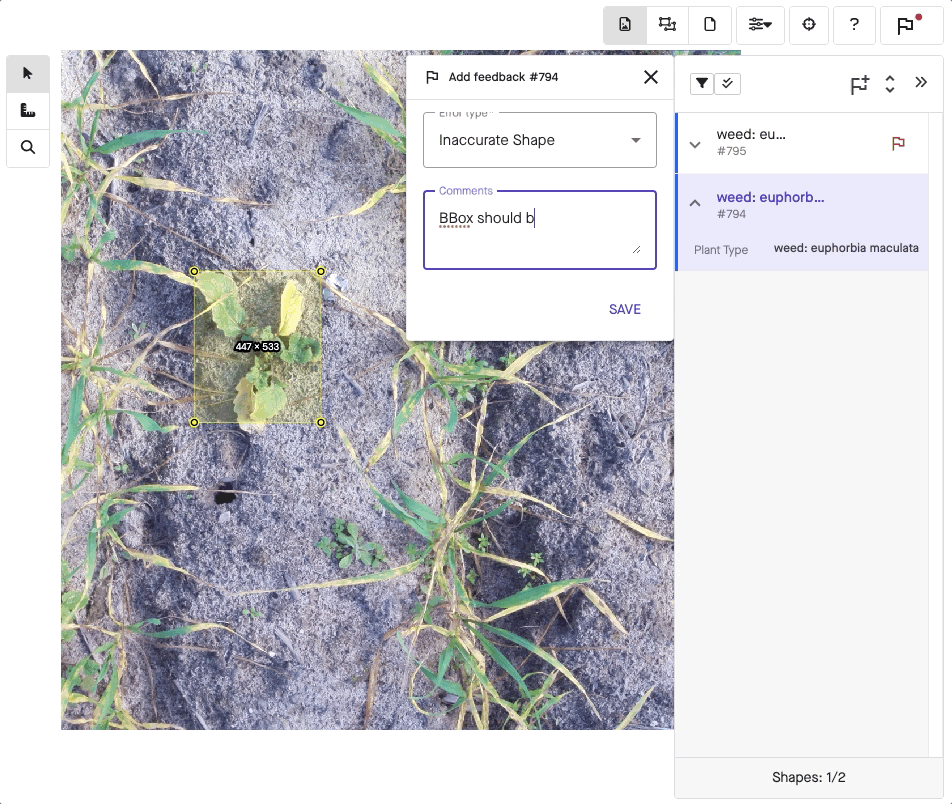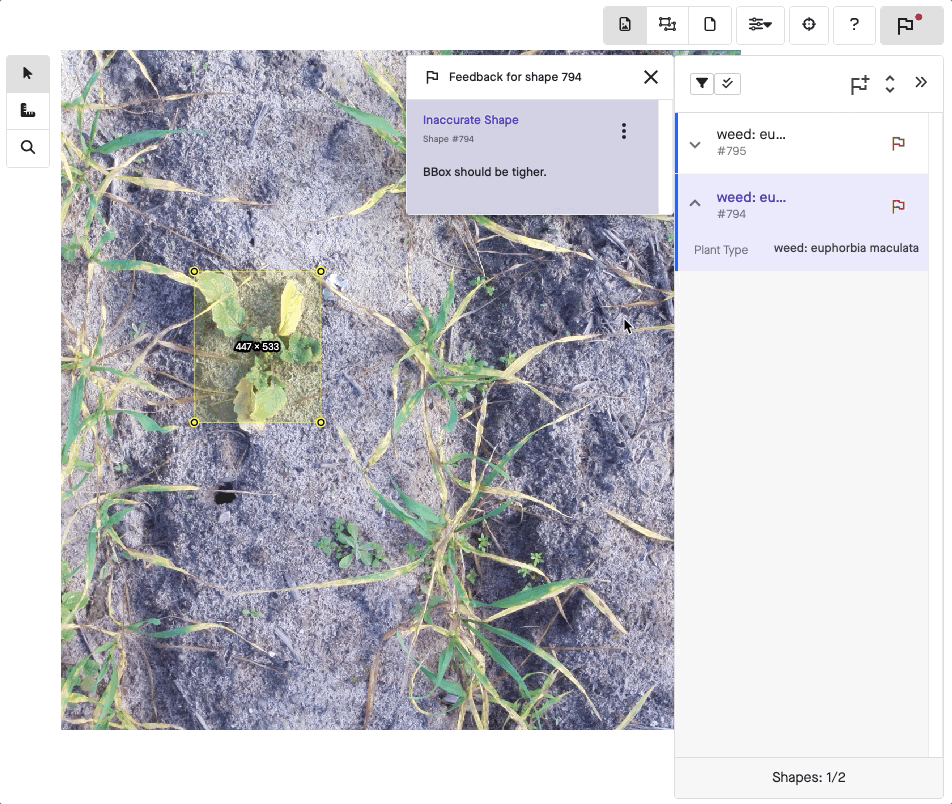
A different labeling method may apply to image annotation. In this case, a labeler adds information to a picture so a model can learn what it represents. For instance, a labeler will draw what’s known as a bounding box, typically a simple rectangle around the subject.
.gif)
Annotated data can contain far more than tags or labels. A fully annotated data set may also include classes, spans, or attributes. The point is that no matter what kind of annotation you use, supervised learning relies on human annotation.
To test this, use a gold dataset: a collection of cleaned, fully labeled data that experts have annotated. When a model’s output matches the gold dataset labels, it’s probably ready for production.
Other kinds of machine learning that involve weaker supervision do not rely as strongly on labeling. They may use heuristics instead. However, humans can still review these models to improve their performance.
Data annotation and quality control help ensure that an AI gives the correct answer to a query. They also help it make accurate predictions and identify everything it needs to find. Using high-quality annotation also ensures that the model will respond correctly when presented with unfamiliar data.
To understand the importance of AI data annotation, let’s look at what happens when people annotate data incorrectly.
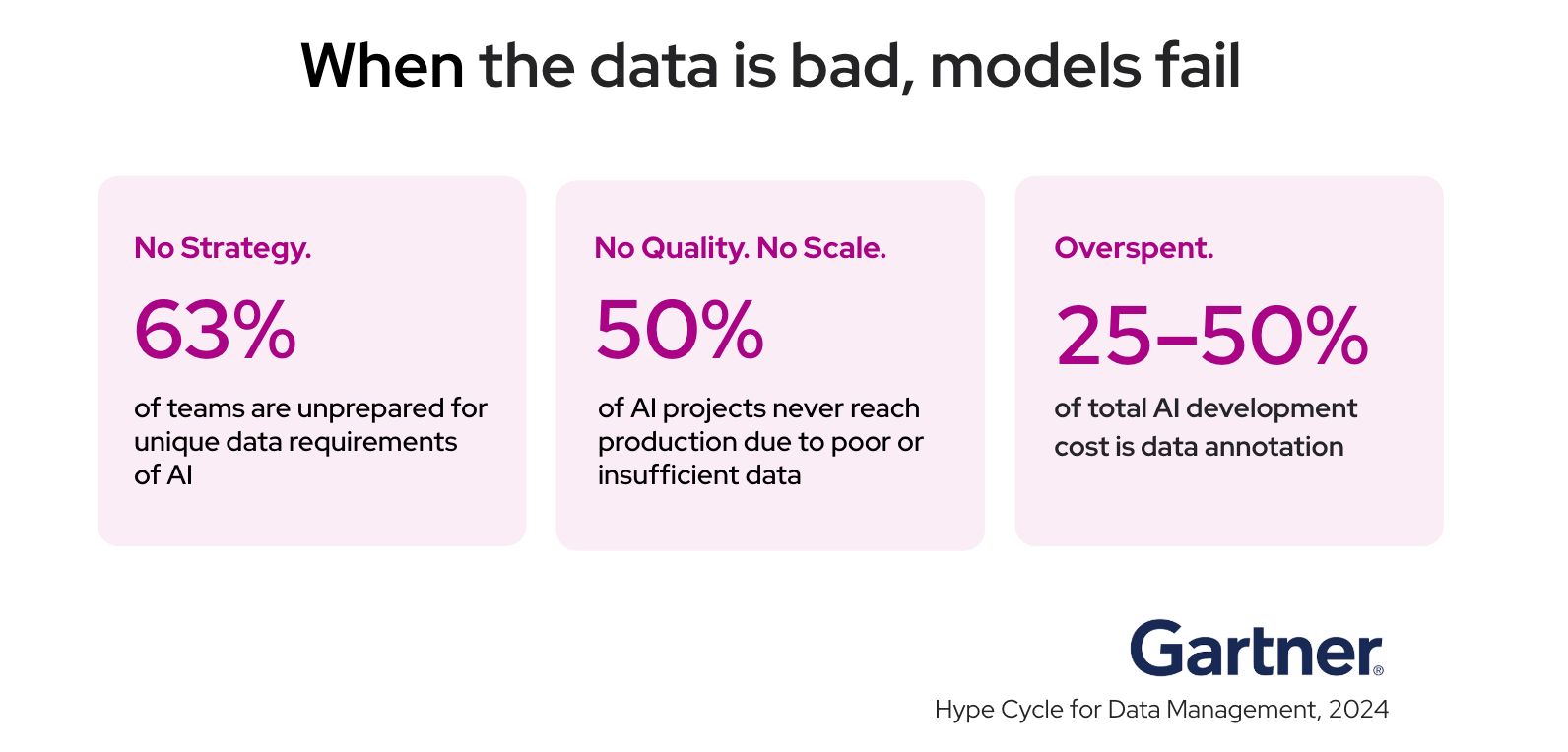
Poor AI data annotations can have negative outcomes for businesses.
Whether you’re using data annotation for consumer technology or a high-tech industry, the quality of the labeler involved with labeling and categorizing the training information is foundational to the performance of the resulting model.
Mastering data annotation means fully understanding the primary types of data annotation as they apply to different media. In this article, we’ll be discussing video annotation, object tracking annotation, activity recognition, and temporal segmentation.

There can be a wide gap between what someone writes and what they mean to communicate. If someone writes “start electric lawnmower how to,” for example, there’s no inherent way for a model to understand that the user is probably looking for a guide.
Semantic annotation is the process of assigning metadata to text that helps machine learning models understand its meaning. Looking at the sentence above, the labeler might highlight the following concepts:
Notice that these concepts are also ranked in the order of relative importance. The most important part of the query is the electric lawnmower. If there are no definitive how-to guides or no guides specific to starting an electric lawnmower, the user will at very least receive some relevant information.
Intent annotation builds on semantic annotation by assigning intent to queries. If a user asks a chatbot, “find me a list of reviews of different brands of electric lawnmowers,” the model will rely on intent annotation to understand that the user is making a request.
Sentiment annotation tells the AI model how the user is most likely feeling when they write a piece of text. As a result, the model can determine whether a review is positive or negative. It can also recognize when a user is particularly frustrated while submitting a support ticket, helping prioritize them for escalation.
Lastly, Named Entity Recognition (NER) is the formalized process of tagging spans of text with labels, highlighting data such as names, organizations, and dates.
Just as with text annotation, there are multiple subcategories of image annotation. Here, we’ll understand image classification versus multi-label classification, when to use bounding boxes and when to use polygons, semantic segmentation versus instance segmentation, and more.
Image classification takes an image and assigns everything in it to a single category. If there’s a picture and the subject is a baby, then that entire picture is categorized as “baby.” But what if you want to categorize the pile of toys in the background? Then you’ll turn to multi-label classification, which identifies multiple objects within the same image.
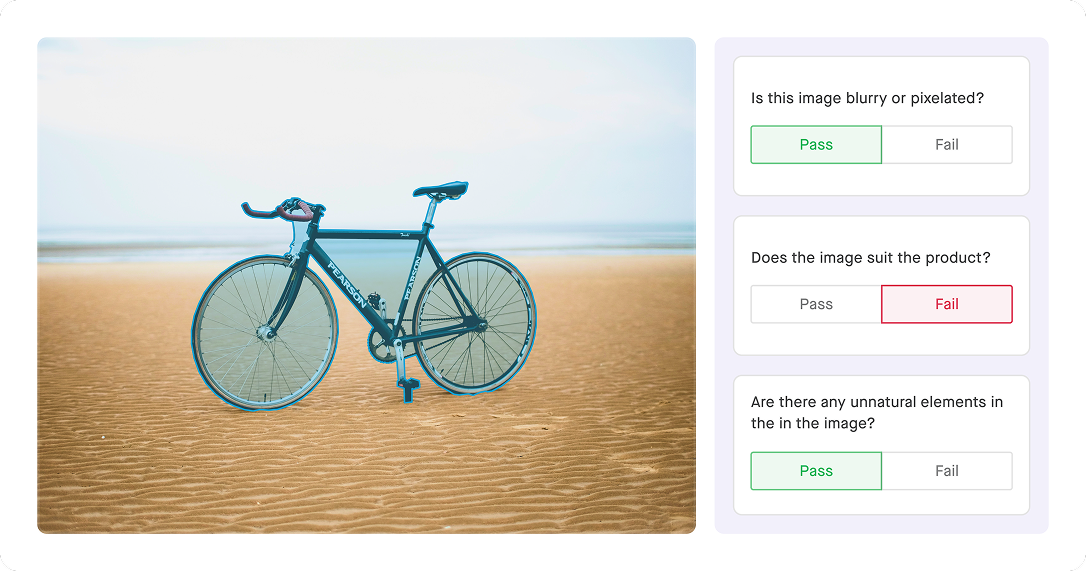
Going a step further, object detection assigns more than just labels. Using either bounding boxes or polygon annotation, the labeler also displays the exact position of an object within an image. Because bounding boxes are just rectangles, it’s easier to draw them when detail isn’t critical. Meanwhile, polygons can show off a lot more detail when needed.
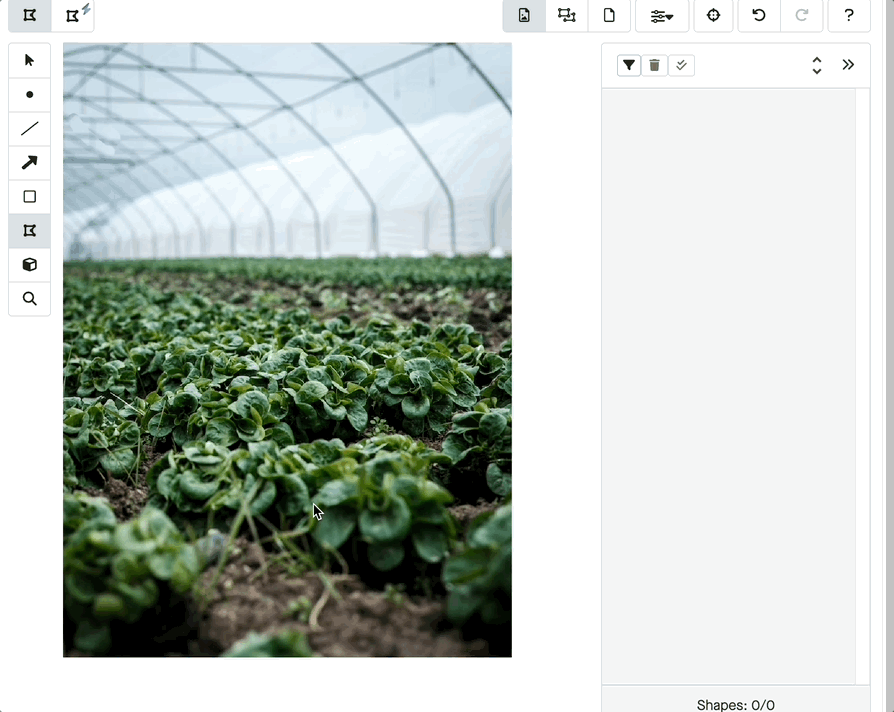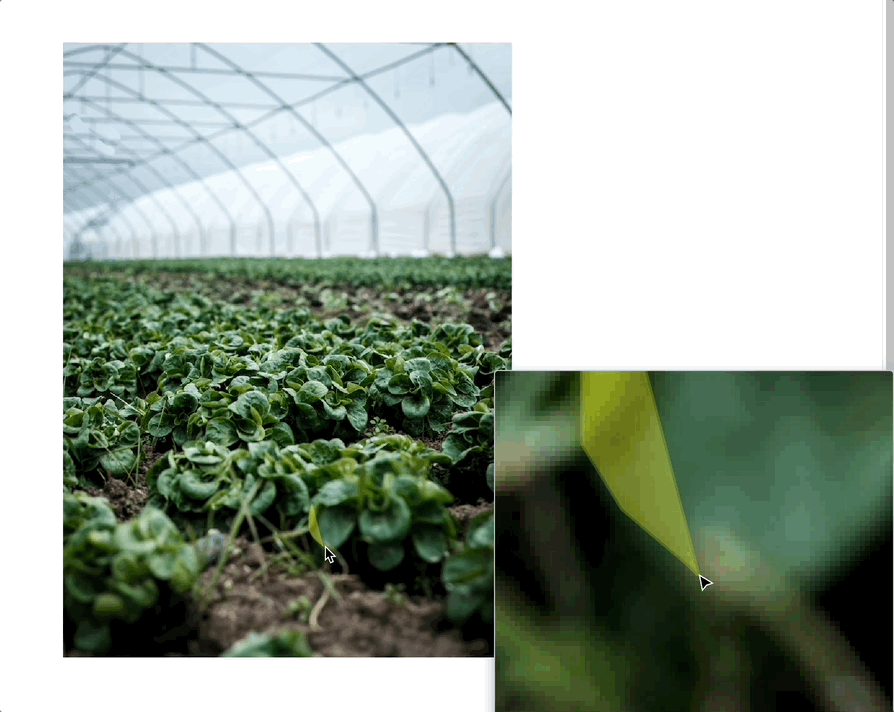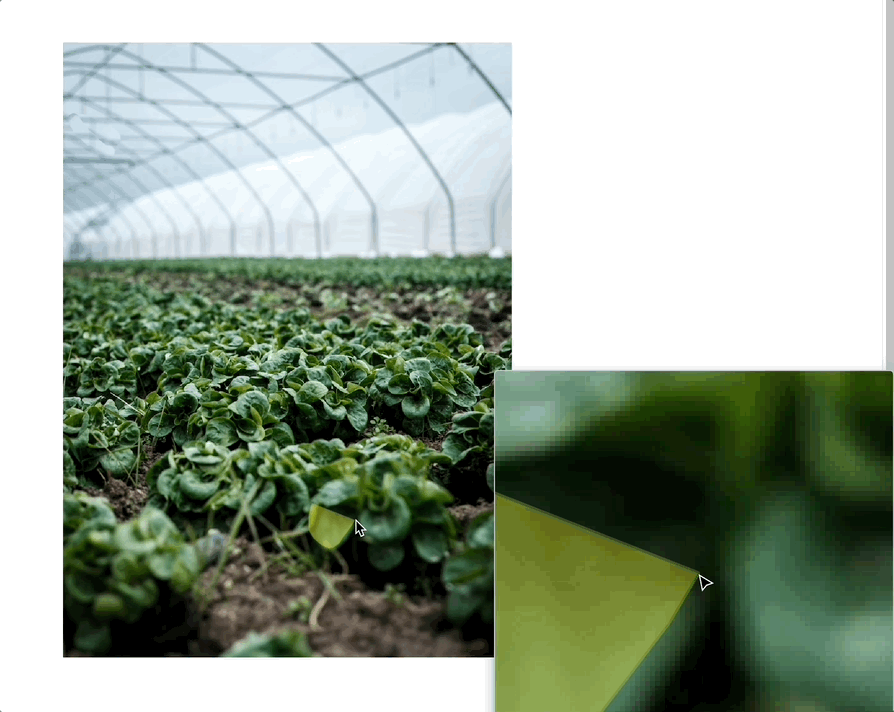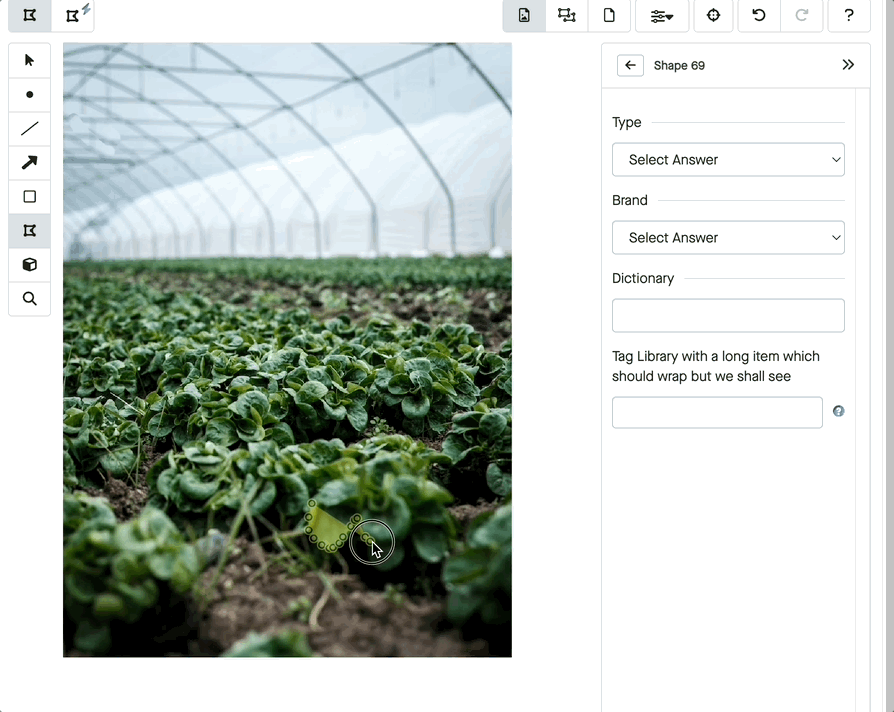
What if you want to label every pixel in an image? Then you’ll turn to either semantic segmentation or image segmentation. What’s the difference?
Lastly, what if you want to know not just the position of every person in a picture, but also details like who they are or where they’re heading? Annotators can train their models by identifying keypoints or landmarks on areas of the human body (or other bodies in motion, such as livestock or industrial machinery).
Establishing specific landmarks on a person’s face, such as the eyes, ears, and nose, can help an AI model estimate a person’s mood or identify them via facial recognition. Alternatively, annotated data can identify landmarks such as a person’s joints, and then tie them together with lines in what’s known as a keypoint skeleton. This structure can help a model understand a person’s pose and predict what they’re doing or what they’re about to do next.
What is a video if not a sequence of images? Some of the methods used in image annotation apply to video annotation, but there are some key considerations.
These two object tracking annotation techniques have different resource requirements. Annotating bounding boxes frame-by-frame is the most direct and precise approach, but it can quickly become time-consuming for longer videos. Interpolation offers a more efficient alternative by sampling fewer frames while maintaining accuracy.
Here’s another question. How does a model know that the person stepping off the curb in one frame is the same person who’s crossing the street in a different frame? The answer involves another training technique, where annotated data includes persistent IDs across time.
Activity recognition adds deeper context. In this process, the annotator labels the specific action that occurs in a video. For example, they might mark a person crossing the street or waiting at a curb. In contrast, temporal segmentation focuses on activity that unfolds over longer and more distinct periods of time. One example would be labeling whether a business is open or closed based on security camera footage of traffic within the store.
Video annotation is one of the most complex activities in machine learning due to the sheer volume of data, making it prone to errors. A primary challenge is ensuring labeling consistency, especially when multiple annotators work on the same video. Without clear standards, annotators may draw bounding boxes with slight differences or vary in the level of detail they include, resulting in a model that tracks objects inconsistently over time.
Managing this requires establishing rigorous and clear annotation guidelines as the foundation for consistency. Rather than relying on a single annotator for a long video, which is often impractical, the focus should be on quality control processes that ensure all annotators adhere to the same standards. Furthermore, teams can maximize efficiency and data quality by:
Compared to image, text, and video, speech and acoustic analysis is a whole different ballgame. Audio annotation requires a different set of skills and techniques, such as speech transcription, compared to data annotation that relies on vision.
Take the process of annotating a noisy conference call with multiple speakers talking at different volume levels. The labeler needs to add timestamps indicating who is speaking when. They may also need to normalize the audio so that everyone appears to be speaking at the same volume, while at the same time leaving the noise and relative dynamics intact.
When more than one person is talking, speaker diarization splits the audio into distinct segments. That way, the model knows who was speaking at each moment in the recording. If the model needs to understand a person’s emotions relative to how they’re speaking, emotion annotation or prosody tags will provide this context.
Lastly, some audio data doesn’t consist of voice recordings. Imagine audio from a busy intersection designed to alert to the sound of a car crash, or a deep-sea sensor array listening for whalesong. Acoustic event labeling is the process of annotating this data to assist a machine learning model.
Across every type of data, there is a need to create a consistent and accurate annotation taxonomy. In data science, experts often organize data using the “mutually exclusive and collectively exhaustive” (MECE) principle. “Mutually exclusive” means that each piece of data belongs to only one category and cannot fit into another. “Collectively exhaustive” means that the categories cover all possible data.
MECE is important because mutually exclusive categorization eliminates redundancy, which optimizes the model for performance. Meanwhile, creating a collectively exhaustive data categorization system helps improve the model’s analytical abilities.
Adhering to MECE is as much of a business process as it is an ontology for data labeling. As a result, changing data sets must be subject to versioning and change management procedures. Change management allows developers to account for data shift and category drift, which can occur when a production model encounters real-world inputs that differ significantly from its training data.
One last important aspect of data annotation taxonomy design is the mapping of labels to downstream actions. If you’re designing an agent, and it encounters data with the label [X], what are the potential actions that it will take? If the model encounters the same data in a different context, will it react in the intended manner? For example, can it distinguish between a pedestrian on a sidewalk and a pedestrian crossing the street? Appropriate and well-organized label schema design will keep your model acting correctly, predictably, and responsibly.
Knowing the types of data annotation is one thing. But what is data annotation when it comes to things like project management and quality control? Here, we’ll delve into best practices for scoping, preparing, and delivering a data annotation project.
To set the stage, tie the data annotation process to specific outcomes. If you want your model to perform in a certain way and convert a specific number of prospects, tailor your annotated data to those objectives.
Your first step is to create a label taxonomy that includes both positive and negative examples. Here is the right way to label our data, and here is the wrong way. Don’t be afraid to get specific. If your annotators are confused by edge cases, then it can slow down the overall process or introduce inaccuracies.
Lastly, your annotation objectives should include both granularity and coverage targets. A good example of this is image recognition. Do you need lower-detail bounding boxes or higher-detail polygons? Do you need to classify everything in an image, or just the primary subject?
Part of the success of a data annotation project depends on the kind of data you choose.
Your model will be inadequately prepared for real-world conditions if it’s only trained on a narrow data set. To succeed, your sampling strategy must capture a diverse data set and accept low-probability, long-tail cases.
To prepare data for annotation, you should adopt a technique known as data cleaning. This process deduplicates data and removes outdated or erroneous information. It also redacts personally identifying information (PII) and anonymizes data that could unmask real-world individuals, helping you comply with global privacy laws.
Lastly, you need to seed gold datasets for calibration. Gold dataset creation means using a known good set of annotated data that experts have validated. This dataset isn’t training data, but rather serves as a goalpost for annotator performance. When your annotators' output matches the gold dataset labels, then they’re likely meeting their quality benchmarks.
Just as there are multiple kinds of data annotation, there are also numerous ways to accomplish a data annotation project. Here are some data annotation services you might take advantage of.
While it is possible to use machine learning for fully automated labeling, we don’t necessarily recommend it unless the task is narrow and well-calibrated. That’s because projects with a broader scope can quickly go off the rails. The labeling AI might start to hallucinate labels in images where they don’t exist, or it could begin to make incorrect predictions based on biases within its programming.
What’s the value of in-house vs. outsourced annotation? Every method has its tradeoffs.
Costs here can be difficult to judge. A full-time, in-house team of subject matter experts (SMEs) can cost significantly more than a team of outsourced generalists. On the other hand, hiring part-time generalists directly might cost less than contracting a team of SMEs. The key is to know when you need to use SMEs or generalists.
If you’re using a provider, they should know how to match the annotators you’ll need to the task they’ll be performing. Image-based annotation usually needs less expertise than text. It’s relatively easy to draw a bounding box around a pedestrian as they cross the street, for example.
The greater problem here is boredom and repetition, which means that the annotation provider needs to be ethical concerning their employees. Bluntly speaking, low-paid individuals who do repetitive tasks for long hours tend to make more mistakes. Therefore, you’ll want to work with a provider who treats workers fairly and makes extensive checks for quality control.
Text, however, may require a higher level of understanding, especially if you’re parsing language that refers to physics, chemistry, medicine, and engineering. Even a relatively generalist text might require an English degree level of reading comprehension. Therefore, a good provider will be able to source subject matter experts who will help maintain accuracy and reduce rework while performing text-heavy tasks.
Annotation guidelines are highly effective tools when deployed correctly. With detailed rules, examples of what and what not to do, and an explanation of potential edge cases, your annotator training will result in a well-functioning model.
Calibration rounds are another important facet of training. Here, the trainer provides sample data for annotators to work with and offers feedback based on performance. When different annotators can produce measurably similar notes on the same calibration data, it results in inter-annotator agreement. This consistency means that your level of training and the guidelines you’ve provided have given your annotators the tools they need.
If you aren’t achieving inter-annotator agreement, you may not be setting them up for success. Make sure that you’re giving annotators tasks appropriate to their specialty and proficiency. To avoid getting anyone in trouble, make sure that all annotators receive training on appropriate privacy and security procedures.
As tasks evolve in complexity or require more knowledge, it may be more difficult for annotators to reach agreement. Therefore, it may be helpful to have more than one annotator look over the same set of data in a process known as peer review.
Expert adjudication is another step in the annotation review workflow. When annotators are performing complex tasks in specialized fields such as physics or medicine, it helps to have an expert, such as a Ph.D, take a final look at the labels to ensure correctness.
What about tasks that are subjective, such as determining whether a person looks happy or sad in a photograph? Here, you can use a process called consensus labeling. If a majority of annotators choose a certain label for a subjective task, then that’s the conclusion you can go with.
There are even more tools you can use to help annotators through complex tasks. Pre-labeling automation involves an algorithm that takes a best-guess approach to labeling, saving on manual effort because human annotators now only need to go through and correct mistakes. Adding active learning algorithms will highlight the most instructive examples and edge cases for human annotators to review. These examples will have a significant impact on your model, allowing your annotators to accomplish a lot of training with less work.
While tracking error rates and improving accuracy are very important to quality, there are other considerations. Throughput, meaning the amount of labels an annotator can process per hour, is crucial. Too slow and your cost-per-label begins to increase. Too fast, and your annotators may be sacrificing quality for speed.
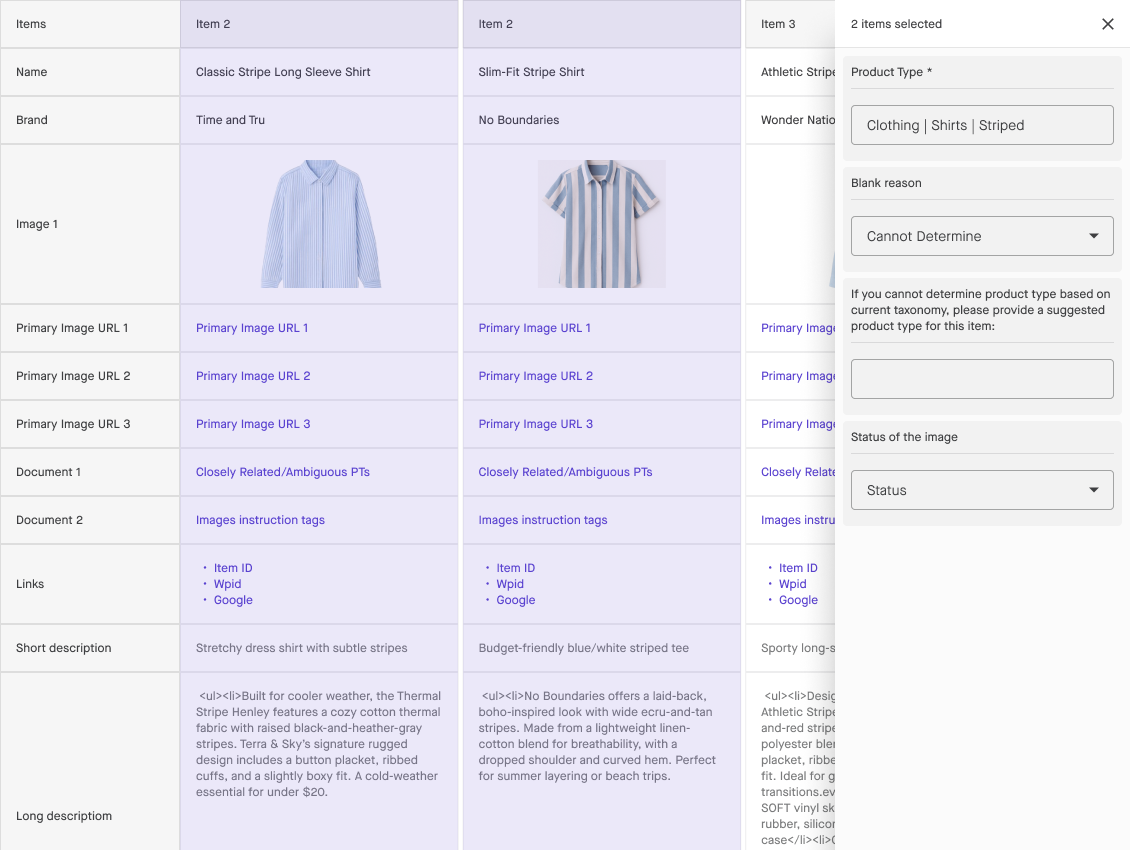
After annotating the data, how do you ingest it into the AI model? There are several annotation export formats that you can choose from:
Each annotation format can support one or more types of data annotation. No matter which format you choose. However, it’s important to employ schema versioning to achieve quality and consistency as your project changes over time.
Data governance is another huge portion of data annotation delivery. There’s a lot that can happen between annotating data and delivering it to production. If bad actors get their hands on it, then it could spell legal and reputational damage for your project. Here are a few security terms you need to know.
Finally, feedback loops help ensure that your data annotation efforts reach their quality benchmarks and maintain them over time. The process typically involves sampling completed work and reviewing it for consistency and accuracy. You can taper sample review rates once quality stabilizes near target levels, but it’s important not to rest on your laurels.

Inter-annotator agreement (IAA) is a key benchmark for measuring annotation consistency across annotators. When all or most annotators agree on how to label a specific piece of data, it shows they’re doing their jobs correctly and that you’ve created a schema with little room for error.
Here are some data annotation metrics you can use to measure IAA.
Gold dataset accuracy is another measurement of annotation quality. Effectively, your gold dataset, a collection of verifiably well-annotated data, can be used as a testing tool to validate your annotators throughout the process. Their output should match the gold dataset in two ways:
Using these metrics, you can set thresholds for quality acceptance. In other words, if a selection of annotated data is less than .8 kappa, it may fail to reach the standard that your model needs to run predictably. Services that offer data annotation support can help your team reach important quality benchmarks.
Throughout this piece, we’ve outlined some of the major processes involved with creating annotated data. Some challenges are big, some less so, but what are the most common data annotation challenges? Here, we’ve created a list of the biggest obstacles that companies can face, plus some hints on how to get past them.
As a company that specializes in creating the AI models of the future, your core specialty doesn’t lie in schema design, human resources, or regulatory compliance. Our considered advice is to employ specialists who will help you master data annotation while you focus on AI innovation.
There is no AI models without data annotation. AI as we know it in the form of LLMs, which is conversational, that can recognize images, identify people in videos, and make decisions, does not exist without annotation behind it.
The process of AI data annotation is often handwaved away as something that happens in the background. But, as we’ve shown, it is a discipline in its own right, with multiple techniques, required expertise, and detailed processes. In addition, the enterprise falls apart without rigorous quality control to keep labels and annotators on track.
Sama specializes in offering data annotation services that can help your AI perform in an accurate, reliable, and repeatable manner. We are currently trusted by 40% of FAANG companies to deliver data annotation services, which power AI used daily by millions of people.
Ready to scale your data annotation projects? Speak with an expert or explore the Sama Platform to see how we can support your goals.
Sama provides ML Professionals and AI team Leads with an indispensable solution for Computer Vision data labeling.
