Text annotation is the process that turns raw language into structured data that machine learning models can understand. This guide outlines the core annotation types, the workflows required to produce consistent training data, and the quality controls needed for scalable programs. Readers will leave with a clear framework for planning, executing, and evaluating text annotation in production environments.

You may have an intuitive grasp of language as a reader, but computer models must be trained to understand it. And while you, as a reader, may have improved your abilities over time, an AI model will only be as capable as the data it’s been trained on.
AI models learn to understand language via the process of text annotation.
Text annotation is when a piece of example writing is parsed and tagged such that an AI model can understand the input. For example, text annotation might identify the subject, object, actions, and sentiments in a piece of sample data.
This guide covers the fundamental processes of text annotation and best practices for achieving high-quality results.
You’ll learn the different types of data annotation for text, plus workflows for each. You’ll also understand how to set up quality control and tooling to create more efficient processes with minimal rework. At the end, you’ll be ready to create your own machine-learning process that can reliably understand, translate, and generate text.
Text annotation is the process of categorizing natural language inputs to make them interpretable for Supervised Learning and Natural Language Processing (NLP) models. In other words, this process enables machines to read, understand, and respond to a variety of language samples.
Three fundamental actions are performed as part of text annotation:
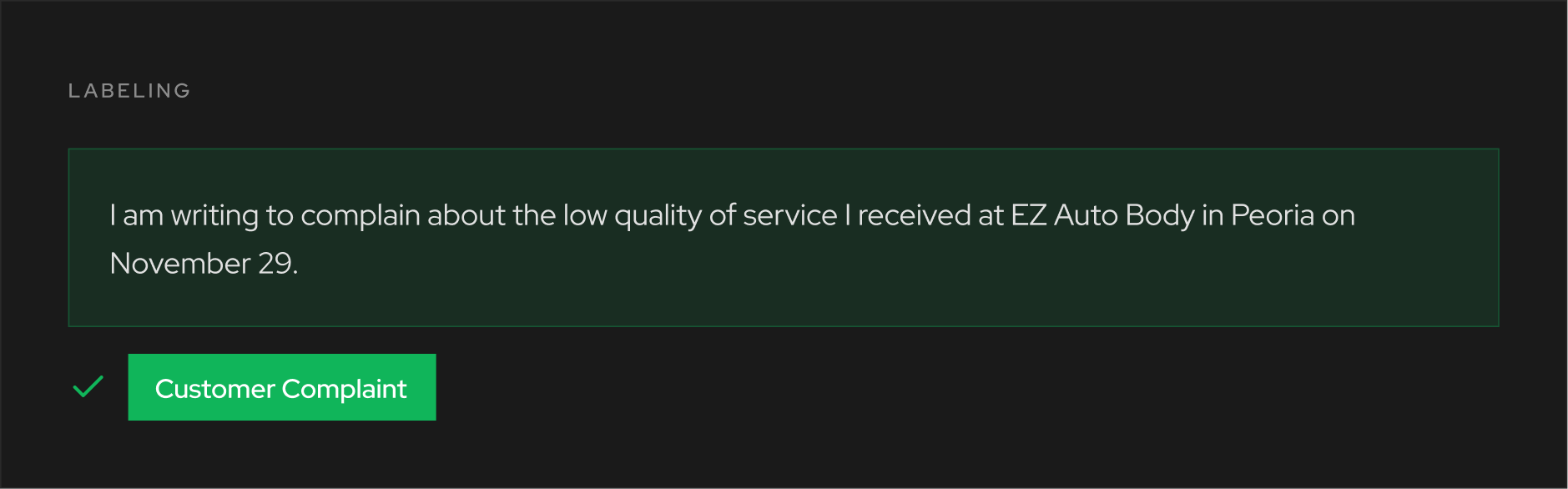
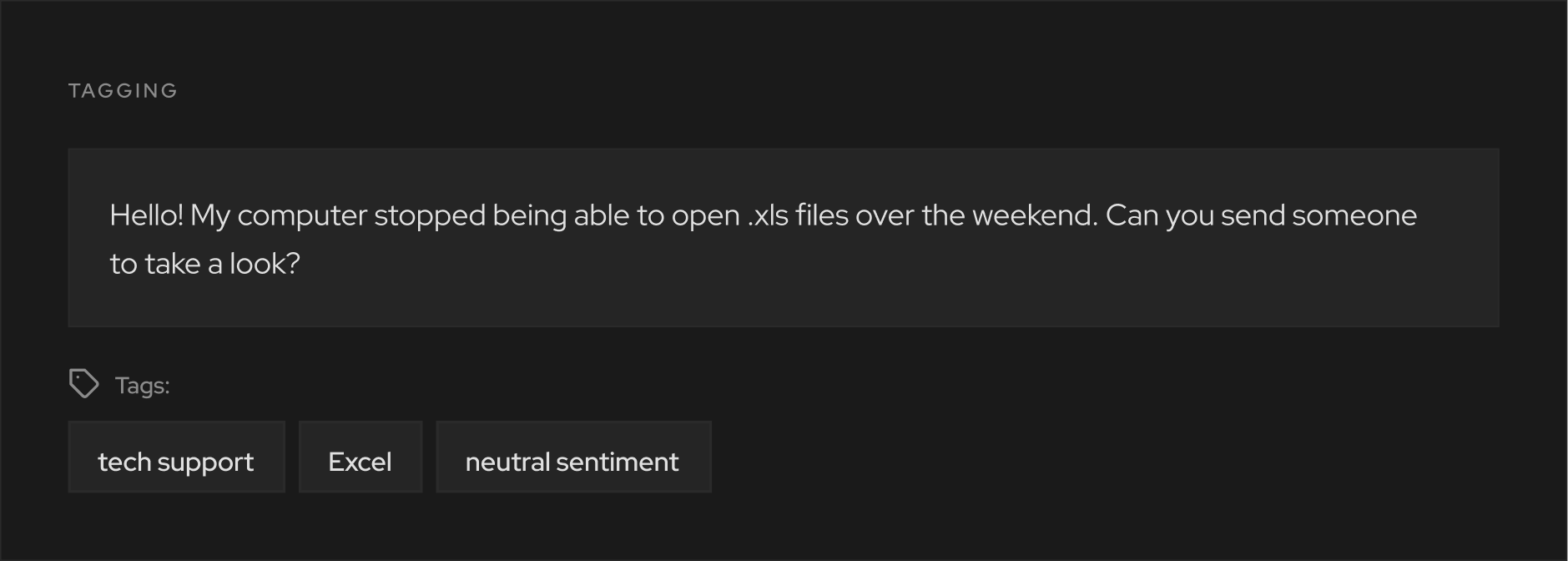
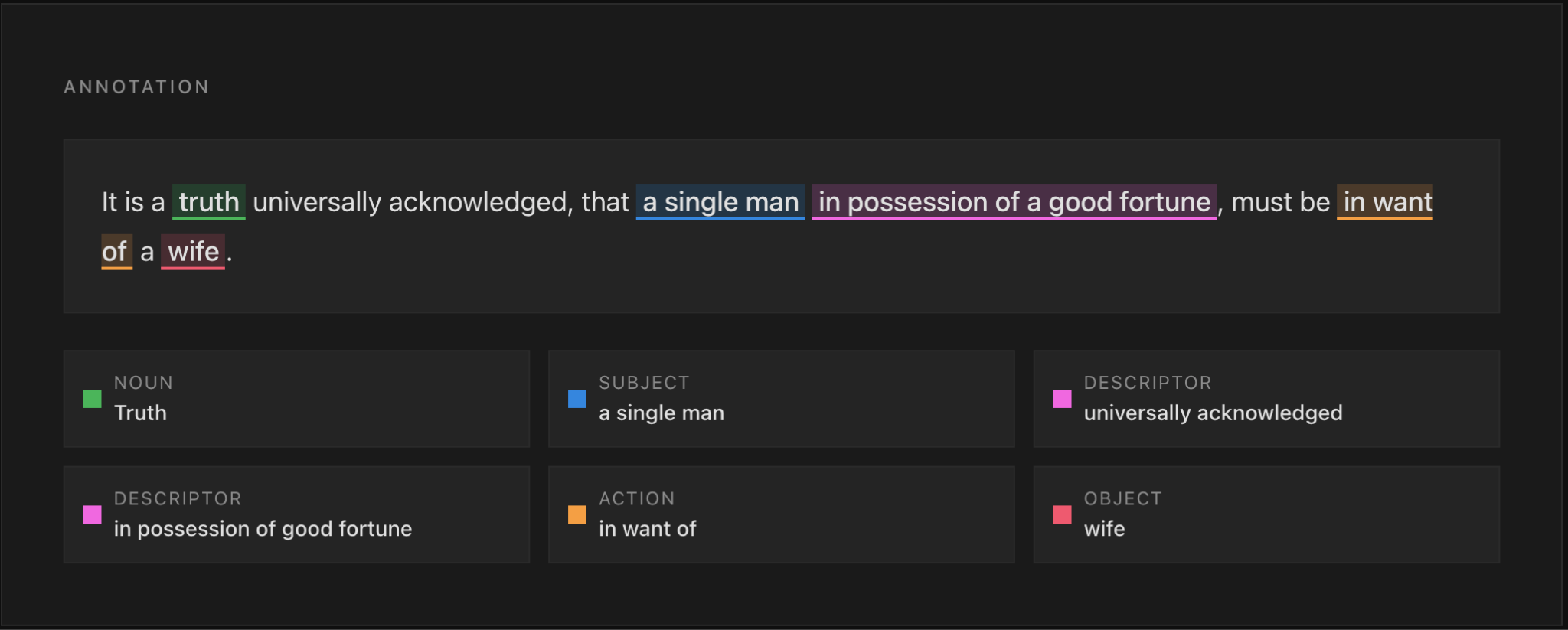
Collectively, these labels, tags, and annotations form what’s known as metadata. Using metadata, machine learning algorithms can identify patterns in sample texts and interpret their content.
There are three main types of text annotation: sentiment and intent analysis, entity recognition and linguistic tagging, and text classification and categorization.
They can be used separately or in combination, depending on the level of understanding needed. Text annotation is one category within the broader data annotation landscape, with each annotation type supporting different model architectures and use-case requirements.
Say that you receive an email saying, “I need to return a defective item, which appears to have been damaged in shipping.” Your machine learning model might not understand anything about the message except the two words “defective item.” Using what’s known as intent analysis, the model would forward the message to the appropriate department (in this case, the Return Merchandise Authorization team).
In another example, let’s say that the email instead says, “My package was damaged during shipping, and I’m going to leave you a bad review on Google!!!” Sentiment analysis might use the phrase “bad review” and the sheer number of exclamation points to flag a disgruntled buyer. They could use this information to escalate the message to a higher support tier.
This brings up a key challenge–the way that people express strong feelings is not necessarily easy to identify. For example, you might receive a comment saying, “My customer support experience at [brand] was so great, my refund never got processed!” To avoid confusing the model, annotators would tag “so great” as a positive descriptor being used to convey negative information (AKA sarcasm). Similar tags can identify additional nuances.
Are people talking about your company when they mention their good or bad experiences? Named Entity Recognition (NER) helps models identify people, places, organizations, and dates that are mentioned in text. Good annotation will enable models to identify whether people are discussing your business, even if they don’t mention it by name.
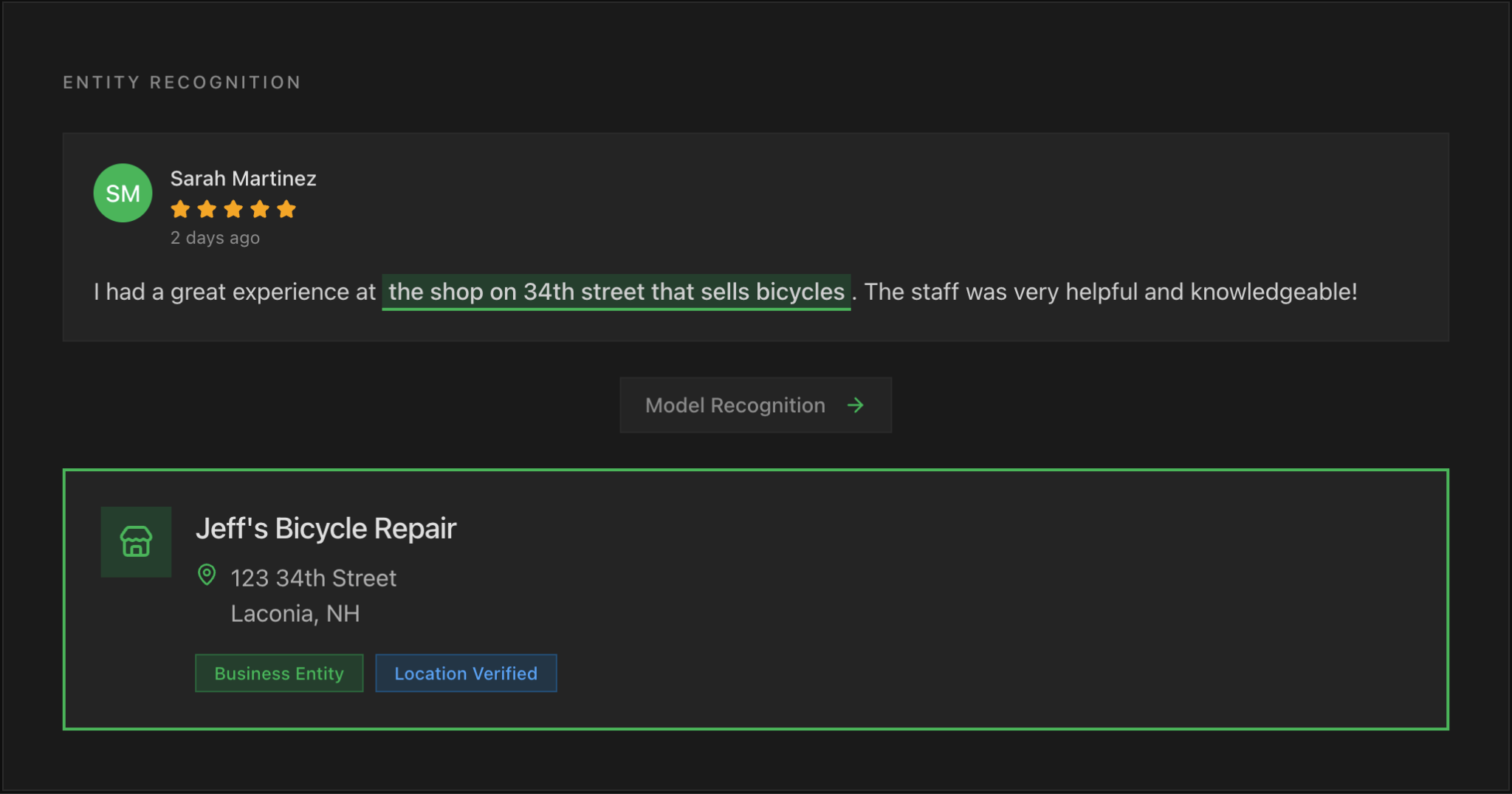
To achieve this level of sophistication, annotators should also incorporate Part of Speech (POS) tagging, which essentially allows models to recognize grammatical structures. By understanding which parts of the text are nouns, verbs, and adjectives, models will be able to achieve a detailed understanding of a text. This is also critical for text generation.
Lastly, what if you only want to understand the main thrust of an entire document? Tools like keyphrase tagging will help extract the general subject of a text for categorization.
Why use text classification and categorization as opposed to more detailed forms of annotation? These tools are sometimes more resource-intensive than the use case requires. Scenarios such as:
For some texts, just one label may be necessary–if a message is marked as spam, it gets deleted. Therefore, it only needs single-label classification. A document in your database may need to be discoverable via multiple search terms. Therefore, it receives multi-label classification.
Text annotation matters for machine learning because model accuracy depends on detailed and accurate annotation. No matter what kind of text annotation you’re using–sentiment or intent analysis, entity recognition, or text classification–reliable output only arises as the result of consistent training data.
Some may not think that text annotation is as important as other types of data annotation, because text is supposed to follow grammatical rules. But much of the language that people use falls outside of grammatical norms. Here’s an example:
An AI model that understands the way that people communicate–instead of just grammar–will produce better business outcomes. Imagine a chatbot that responds more realistically to disgruntled customers, content moderators that are faster to remove unsafe content, and search engines that surface more relevant information.
On the other hand, imagine a model that responds stiffly, slowly, and less accurately, and how that might affect your business performance. Poor training data will lead to failed deployments.
Consistent instructions, diverse training data, and detailed review processes are key to achieving success in text annotation.
To ensure your model responds reliably, different annotators must provide similar annotations for the same text sample. This means creating clear guidelines for annotation.
At a minimum, an instruction set must include the following:
Guidelines don’t have to be set in stone. As the model and its features develop over time, guidelines should change to enable them.
After creating text annotation guidelines, model creators will need to make some choices, starting with the extent of their training data. This will depend on your use case and the level of accuracy required. If you’re creating an AI to parse the intent of customer reviews, you may need less data than if you were trying to make a convincing chatbot. Therefore, you might select only one out of every ten reviews received over one year, rather than annotating all of them.
Regardless of your data selection, you will normally follow a standard Human-in-the-Loop workflow:
Eventually, the number of low-confidence predictions falls below a defined threshold (again, depending on the use case), indicating the model is ready for production.
The next big choice, however, is which humans (employees) you’d like to loop in. One option is managed teams, with full-time annotators hired in-house or contracted through an agency. These provide higher quality and security, which is useful if you need to protect your IP. The other choice involves crowdsourcing temporary annotators, which reduces cost at the expense of variable quality.
Annotated data is somewhat unique in that it needs to be readable both by people (who aren’t necessarily programmers) and machines. This means your annotated data must be exported in specific formats. Here are some of the common examples:
No matter what format you choose to export annotated data in, you should include some additional metadata that specifically cites your data preparer. This should consist of a timestamp (when the data was prepared) and the annotator's identity. This will enable tracing the training data back to a specific labeler or annotation team for quality control.
Once you have created your annotation guidelines, the next step is to ensure that annotators adhere to them.
Do your annotators provide similar labels when confronted with the same piece of text? The extent to which their labels agree is known as Inter-Annotator Agreement (IAA) or Consensus. A model trained on data with a high degree of IAA will provide more accurate and consistent responses, making this a benchmark metric for consistency.
There are a few ways for developers to measure IAA and other quality metrics.
So, what happens when annotators disagree or provide low-quality output? Sometimes, this means retraining or replacing the annotator in question. If you find that your annotators are providing inconsistent output on the same set of labels, however, it might not be their fault. Consider refining your guidelines to provide more detailed instructions.
As you encounter success, you will likely need to grow your team in order to add new features or perform supervised fine-tuning. As you add more headcount, however, you’ll encounter personnel at different levels of training and experience. This may make it difficult to maintain consistency.
It’s therefore critical to establish feedback loops between data scientists and annotators during the scaling process. Data scientists can help measure consistency, and annotators can provide input on existing guidelines. This allows annotation teams to improve their metrics as they grow.
Adding more guidelines is usually the best way to address questions about consistency. A potential drawback is that more guidelines tend to increase model accuracy at the expense of speed. However, customers will usually prefer a model that provides better answers. If you want to keep scaling, it’s in your best interest to make the most reliable model you can.
You could perform data annotation with nothing more than a word processor and a spreadsheet, but you’ll likely get better results with a purpose-built tool.
What should you look for?
Ease of use
Security
While it’s possible to build your own data annotation tools in-house, there are definite disadvantages. Primarily, your team is an AI development firm, which means that creating a data annotation tool–with the security and quality-of-life features that you need–may be outside your core competencies.
That being said, even the best data annotation platform is only as good as the team using it. That’s why Sama is currently used by many of the world’s largest AI innovators to provide reliable and high-quality generative AI services at scale.
Although AI chatbots and text-generation tools are seemingly everywhere, this aspect of machine learning remains far from solved. It’s still possible for new companies to dislodge incumbent players, but the foundation of their success will rest on their training data.
Because high-quality training data is the competitive advantage in AI development, it’s important to choose the right annotation type and maintain strict quality control. Make sure to check your current data strategy against our recommendations. And if you’re already following all of the best practices in this guide, then it may be time to take the next step.
Sama is one of the benchmark providers for high-quality data annotation across the AI industry.
As a trusted partner for many of the leaders in this marketplace, we can help by putting you in touch with one of our experts who can manage your annotation requirements.
Talk to an expert to start a pilot with us before you scale and learn how we can validate your data annotation approach.
Sama provides ML Professionals and AI team Leads with an indispensable solution for Computer Vision data labeling.
