Taxonomy categorization assigns consistent hierarchical labels to items across catalogs and content systems. This guide explains how to design labelable taxonomies, run production workflows, and maintain quality through calibration, agreement measurement, and ongoing QA. It also clarifies when to use taxonomy classification, attribute extraction, or category mapping at scale.

Taxonomy categorization underpins how products, content, and model outputs are organized across modern digital systems. As catalogs, content libraries, and AI-driven workflows scale, maintaining consistent categorization becomes increasingly difficult.
Items are added faster than taxonomies evolve. Source data is often incomplete or inconsistent. Category structures change as organizations expand into new markets, introduce new offerings, or integrate acquisitions. Each of these factors introduces ambiguity into categorization decisions.
Many organizations treat taxonomy categorization as a one-time labeling task. In production systems, this approach does not hold. Without explicit definitions, structured workflows, and ongoing quality controls, category decisions drift over time.
That drift does not stay isolated. Inconsistent taxonomy signals degrade search relevance, distort analytics, and introduce noise into model training, evaluation, and ranking features. Once embedded in downstream systems, taxonomy errors become slow, expensive, and disruptive to correct.
This guide explains how taxonomy categorization works as an operational system in production. It covers:
The guide is intended for product, data, and machine learning teams responsible for maintaining consistent categorization across catalogs, content systems, and AI-driven workflows.
Taxonomy categorization is the process of assigning one or more labels from a predefined hierarchical category system to an item. This hierarchy defines how categories relate to one another, enabling consistent data organization.
Taxonomy categorization applies to many different data types across modern systems.
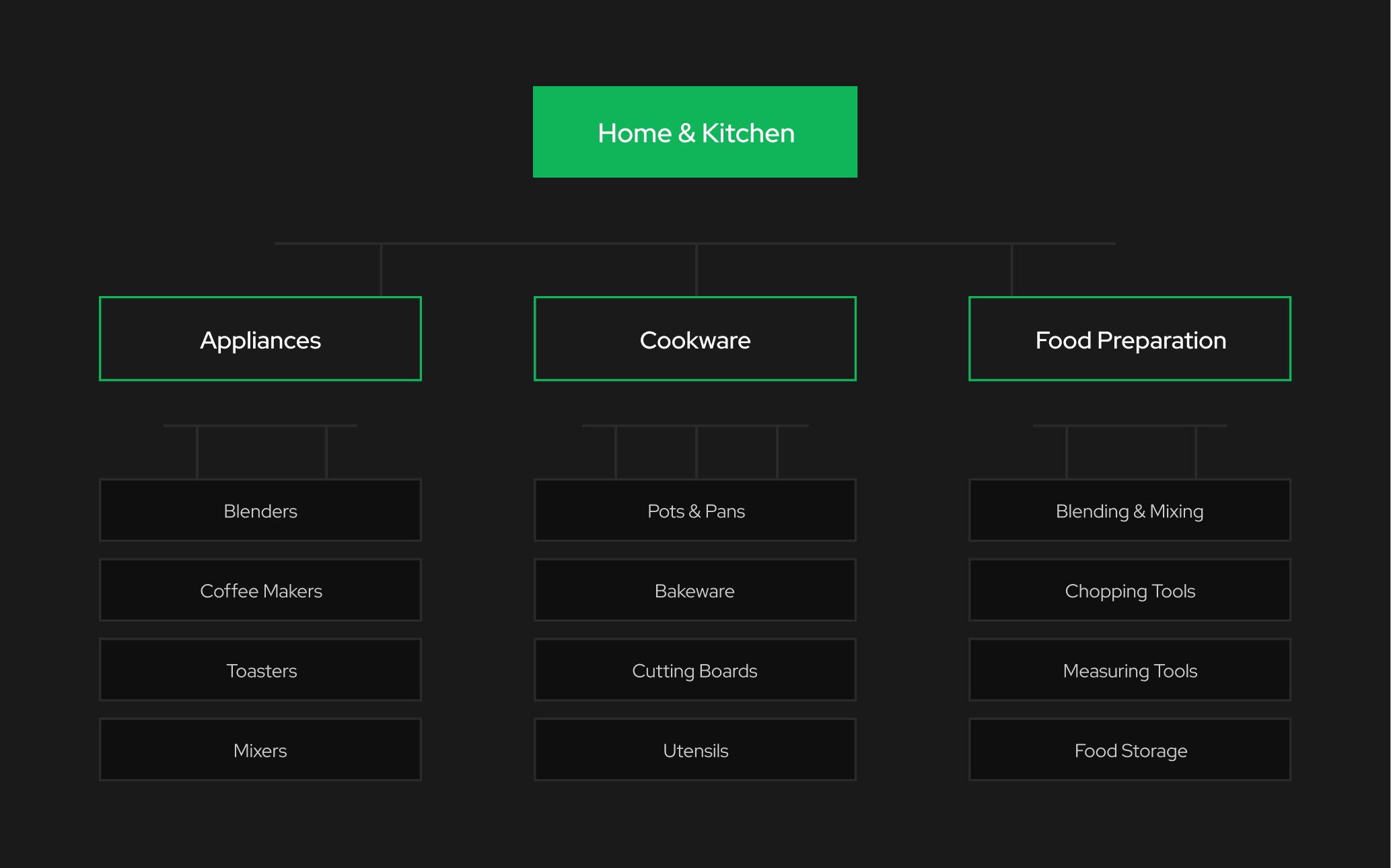
Categorization can occur at the item, document, or output level. At each step, different sources of ambiguity can arise. The challenge increases when taxonomies evolve or when multiple category paths appear equally valid. Here’s an example. Let’s say you’re working on the product taxonomy for a blender. It might belong under:
Home & Kitchen → Appliances → Blenders
That’s logical. However, it really might need to be classified as:
Home & Kitchen → Appliances → Small Appliances → Blenders
While similar, labeling mistakes like these can distort your database. Yet, without explicit rules, both choices appear reasonable.
Taxonomy categorization is foundational infrastructure. It supports multiple systems that users interact with every day, even when it is not visible.
In product and catalog management, taxonomy categorization enables consistent browse structures, catalog cleanup, and SKU normalization. It allows teams to manage long-tail inventory and align vendor-provided categories with internal standards.
In search and personalization systems, category signals influence ranking, navigation, filtering, and recommendations. Misclassified items reduce relevance, limit conversions, and distort personalization logic, particularly in large eCommerce taxonomies.
In customer experience systems, taxonomy categorization routes tickets, classifies customer intents, and supports automation. Incorrect categories can delay resolution, misroute requests, or introduce unnecessary escalation.
In media, advertising, and compliance, categorization supports content classification, suitability labeling, and reporting. Errors here can hurt ad performance and also introduce increased regulatory or policy risk.
When the cost of errors is high, or taxonomies are especially complex, many teams rely on managed human-in-the-loop operations to maintain consistent category decisions over time.
Not all classification problems are the same. Understanding the difference between taxonomy classification, attribute extraction, and category mapping is important to prevent teams from using the wrong approach.
Taxonomy classification assigns one or more nodes from a hierarchical category tree.
Best suited for: Navigation, browse structure, analytics rollups
Attribute extraction focuses on structured fields such as brand, size, color, or material.
Best suited for: Improving filtering, recall, and structured search, often complementing taxonomy rather than replacing it.
Category mapping translates items from one taxonomy to another. For example:
old → new or vendor taxonomy → internal taxonomy
Best suited for: Platform migrations, M&A, and marketplace onboarding.
Category mapping becomes critical during platform migrations, mergers, or when onboarding third-party catalogs that use different category structures.
Which approach is right for you? Consider:
A taxonomy that looks logical in a diagram can still fail in production. Labelability depends on whether humans can apply categories consistently using the evidence available to them.
Label definitions must be discriminative by nature. Each category should clearly state what belongs and what does not. Overlapping sibling categories create situations where multiple answers feel correct, leading to inconsistent labeling.
Depth also introduces tradeoffs. Deep hierarchies increase your precision, but may also increase ambiguity and increase labeling time. Shallow hierarchies reduce ambiguity, but may lack the granularity you need for personalization or analysis.
Designing for labelability requires more than category names. You need:
If frequent taxonomy changes are expected, versioning and mapping should be planned from the beginning rather than added reactively.
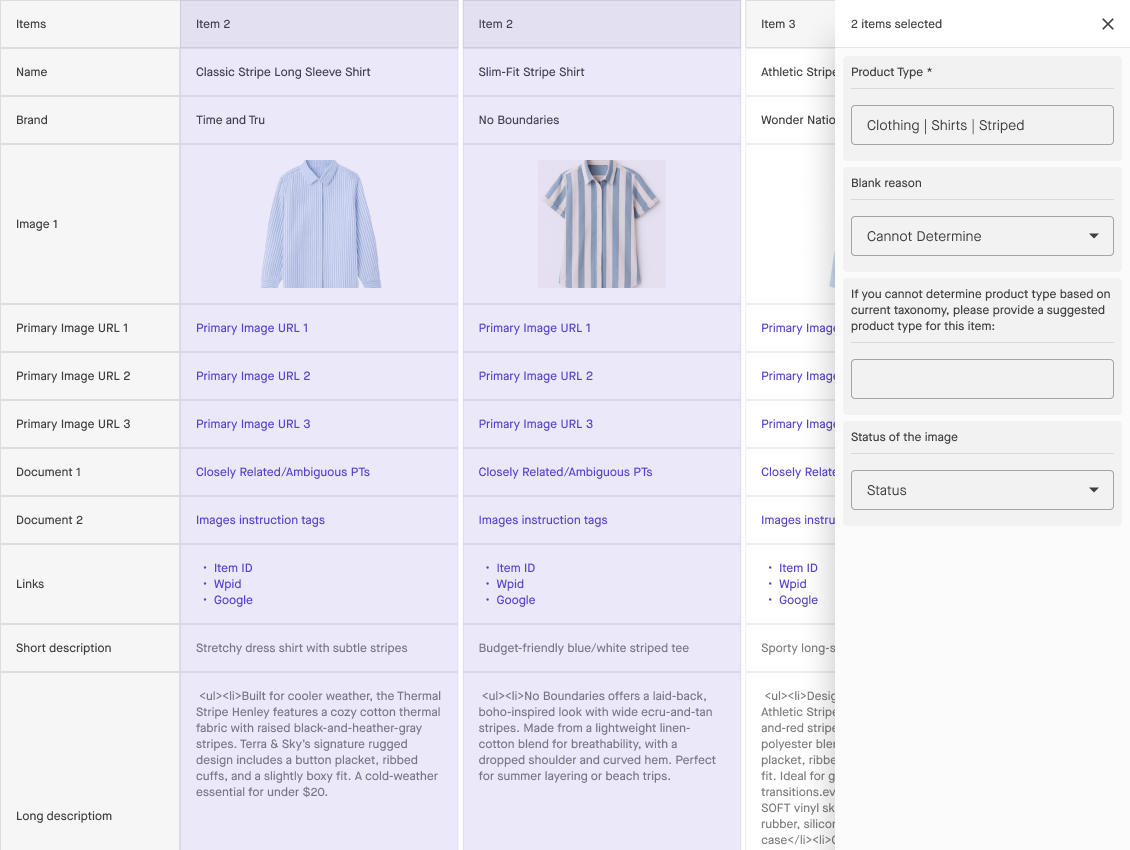
Taxonomy categorization is an operational workflow with multiple stages, and how you execute will vary based on your volume, complexity, and accuracy requirements.
Some workflows involve single-item decisioning, where reviewers evaluate each record independently. Others use bulk or table-based workflows to maximize throughput for consistent catalogs. Comparative workflows support decisions between candidate categories or the evaluation of model suggestions.
Regardless of the workflow pattern, taxonomy categorization in production follows a predictable operational flow:
Managed human-in-the-loop providers like Sama can support these workflows using trained teams, rubric-driven labeling, calibration rounds, and structured QA.
Quality control in taxonomy categorization depends on clear labeling rules, reviewer calibration, agreement measurement, and continuous QA sampling. When these controls weaken, inconsistency and drift quickly follow.
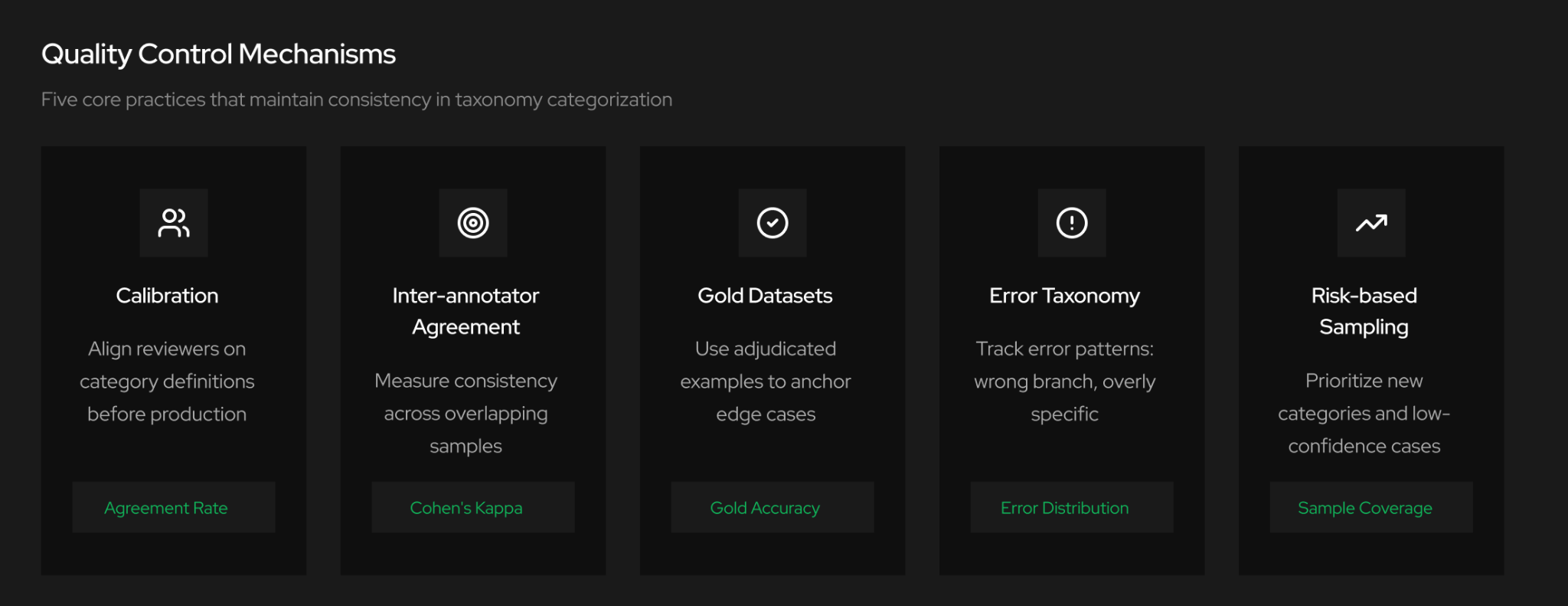
Quality assurance relies on repeatable processes, including:
Taxonomy errors don’t stay contained; they impact performance downstream, including degrading the search experience and distorting analytics. In AI and machine learning systems, taxonomy decisions often serve as training signals, evaluation labels, or ranking features. Inconsistent categorization, therefore, compounds over time, degrading model performance, skewing analytics, and increasing the cost of retraining and correction.
.png)
Most taxonomy failures follow predictable patterns. Here are some of the common areas where things fall short:
These challenges are why many organizations rely on managed human-in-the-loop operations, such as those provided by Sama, to enforce consistency through standardized decision rules and ongoing QA.
Tools and operating models determine how efficiently taxonomy categorization can scale. When you are considering platforms for taxonomy categorization, look for these tooling capabilities:
Managed models often pair dedicated teams with secure platforms like Sama and defined service levels.
Regardless of whether you have a fully in-house team, a hybrid approach, or a managed solution, security is crucial. You need high-level access control and a secure environment to protect your data integrity.
Launching a taxonomy categorization effort is easier when you make key decisions upfront to avoid course corrections later on. This checklist can help you get started:
Taxonomy categorization works best when it’s treated as an operational system that evolves alongside catalogs, taxonomies, and downstream decision-making systems. As a living process, you need clear definitions, structured workflows, and continuous quality control to maintain stable performance over time.
For organizations that require managed human-in-the-loop execution, providers like Sama support taxonomy classification and attribute enrichment at scale.
Sama provides ML Professionals and AI team Leads with an indispensable solution for Computer Vision data labeling.
