Model drift is the gradual loss of a production model's accuracy as real-world data shifts away from what it learned during training. This guide breaks down the three primary types of drift (data, concept, and label), what causes them, and how to detect drift early using performance monitoring and statistical tests. You'll also learn the prevention practices that keep retraining efficient and models accurate over time.

A model that hit all your accuracy benchmarks last quarter can quietly become unreliable as the data it encounters in production diverges from what it learned during training.
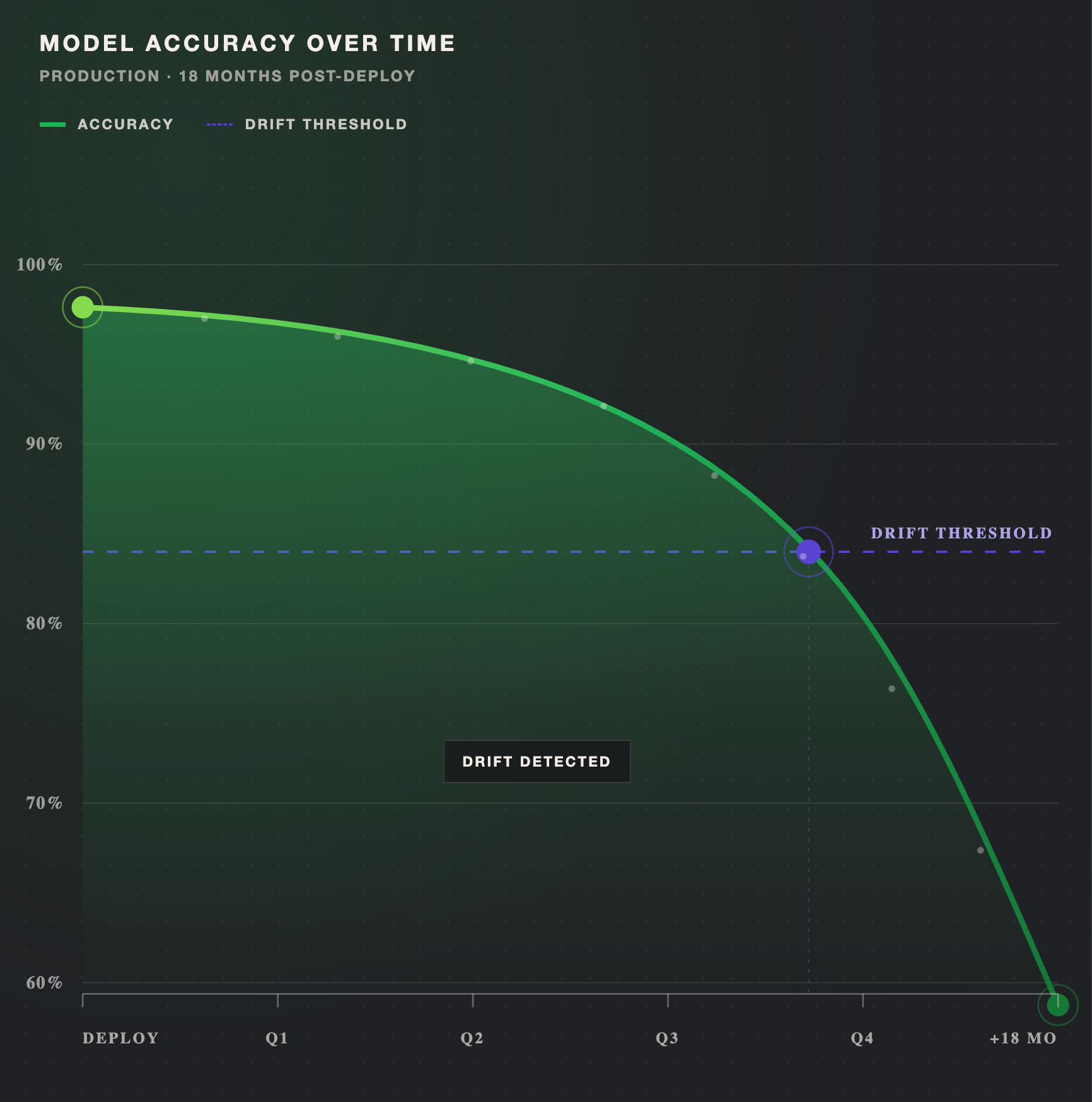
This degradation, known as model drift, affects every production ML system eventually. The underlying cause varies: sometimes the input data shifts, sometimes the real-world patterns the model learned no longer hold, and sometimes the labels themselves evolve.
This guide breaks down the three primary types of model drift, what causes them, how to detect them, and what to do when they appear.
Model drift is the gradual degradation of a machine learning model's predictive performance caused by changes in data or the relationships between inputs and outputs after deployment.
The root cause is straightforward. Models learn static patterns from historical data, but real-world environments are dynamic. A fraud detection model trained on 2023 transaction data may struggle with 2025 purchasing patterns. A content moderation classifier built on one set of community norms can miss emerging categories of harmful content. The model hasn't changed, but the world it operates in has.
You'll also see this phenomenon referred to as model decay or model degradation. These terms describe the same core issue: a growing gap between what the model learned and what it now encounters in production. The gap tends to widen gradually, which makes drift dangerous. There's rarely a single moment when the model "breaks." Instead, predictions become slightly less reliable over weeks or months until the cumulative effect surfaces as a measurable business problem.
Model drift is an umbrella term that encompasses several distinct phenomena. Understanding which type of drift is affecting your model determines how you respond, and the next section breaks down each type.
Model drift breaks down into three primary categories, each with different causes and different implications for how you respond. The most common distinction in practice is data drift vs concept drift, but label drift adds a dimension that most teams overlook.
Data drift, also called covariate shift, occurs when the distribution of input data changes over time while the underlying relationship between inputs and outputs remains the same. The model's logic is still correct, but it's seeing inputs that fall outside the range where it performs reliably.
Real-world examples are common. User demographics on a platform shift as the product scales to new markets. Seasonal purchasing patterns change the mix of products flowing through a recommendation engine. New product categories appear in an e-commerce catalog that weren't represented in the training data.
Data drift is often the easiest type of drift to detect because you can directly compare input feature distributions between training data and production data. Statistical methods like the Kolmogorov-Smirnov test or Population Stability Index (covered in the detection section below) are designed for exactly this comparison. Data drift is also frequently the first type of drift to appear, since production data rarely stays static for long.
Concept drift occurs when the relationship between input features and the target variable changes. The patterns the model learned during training no longer hold, even if the inputs themselves look similar.
This is the more fundamental of the two drift types. Where data drift means the model sees unfamiliar inputs, concept drift means the model's learned rules are wrong. A sentiment analysis model trained before a major cultural shift may misclassify opinions that would have been interpreted differently a year earlier. A credit risk model trained during economic stability will apply rules that no longer hold during a recession.
Concept drift takes four forms, each distinguished by pace and pattern:
Understanding which form of concept drift you're facing determines the urgency and scope of your response. Sudden drift may require immediate retraining, while recurring drift may call for seasonal model variants or broader training distributions that account for cyclical patterns.
Label drift occurs when the distribution of the target variable shifts over time, even when input features and their relationship to the target remain stable.
Consider a fraud detection model trained when fraudulent transactions accounted for 1% of all activity. If fraud rates increase to 5%, the model's decision thresholds, calibrated for the original distribution, will produce different error profiles. False negatives may spike because the model's prior assumptions about base rates no longer hold.
Label drift is particularly relevant for classification systems where class proportions fluctuate. It's also the type of drift most directly connected to training data management. When label definitions evolve or class distributions shift, the training data needs to reflect those changes. This is where data annotation workflows play a direct role. Refreshing labeled datasets to match current real-world distributions keeps the training set aligned with what the model encounters in production, and prevents stale class ratios from degrading performance.
Drift doesn't appear randomly. It traces back to specific, identifiable changes in the environment the model operates in.
Demographic shifts, adoption of new technologies, and cultural trends all reshape the data a model encounters. A recommendation system trained on one user population will see its input distributions shift as the product expands to new geographies or age groups.
Economic downturns, policy or regulatory changes, and unexpected disruptions (health crises, supply chain shocks) can alter the patterns a model was trained on. These events are difficult to anticipate but straightforward to identify after the fact.
Upstream schema modifications, changes in how features are measured or collected, and unit conversions can introduce drift without any change in the underlying phenomenon. This type of drift is particularly insidious because it looks like the real world changed when actually the data collection process did.
Models trained on narrow distributions or insufficient edge case coverage will encounter drift sooner. The model isn't wrong about what it learned. It simply didn't learn enough of the real-world variability to remain accurate as production conditions evolve.
When model outputs influence future training data, self-reinforcing patterns emerge. A content recommendation model that surfaces certain content types more frequently generates more engagement data for those types, skewing future training toward a narrower slice of user preferences. Search ranking models face the same dynamic: users click on top results more often regardless of relevance, and those clicks become training signal that reinforces existing rankings. Breaking feedback loops usually requires introducing external ground truth or diversified sampling into the training pipeline.
Effective drift detection combines automated statistical monitoring with human evaluation. Neither approach is sufficient on its own.
Tracking accuracy, precision, recall, or F1 scores over time is the most direct signal that something has changed. Pay particular attention to slice-level metrics: aggregate performance numbers can mask localized degradation. A model may maintain 95% overall accuracy while a specific user segment or product category drops to 80%. Monitoring at the slice level catches these problems before they compound into visible business impact.
Statistical tests quantify distributional shifts in input data, giving you an objective measure of whether drift is occurring.
These methods work best on structured, numerical features. For text and unstructured data, embedding-based similarity metrics or topic distribution comparisons can serve a similar function.
Set thresholds for drift indicators that trigger notifications before performance degrades significantly. Threshold-based alerts catch sudden shifts (a feature distribution diverges sharply from baseline). Trend-based alerts, reviewed weekly or monthly, surface gradual degradation. Slice-based alerts flag localized failures in high-impact segments, allowing teams to respond before the problem reaches aggregate metrics.
Statistical tests detect numerical shifts, but they don't capture qualitative changes: categories that need redefinition, edge cases that require updated guidelines, or shifts in how "correct" should be defined. Structured review workflows, where calibrated reviewers evaluate model outputs against current standards, complement automated monitoring by catching the kinds of drift that numbers alone miss.
Sama's data validation capabilities support this human evaluation component, providing structured review processes that teams need alongside their automated detection systems.
Drift is not a question of "if" but "when." The goal is not to prevent it entirely, but to detect it early and respond systematically.
These practices fit within a broader model maintenance lifecycle. For the full picture on monitoring, evaluation, and retraining workflows, the Model Maintenance Guide covers the complete operational framework.
Model drift is an operational reality for every production ML system. The distinction between data drift and concept drift determines whether you need new training examples or fundamentally different learned patterns. Recognizing label drift adds a dimension most teams overlook, one that connects directly to how training data is managed and refreshed over time.
The teams that handle drift well share a common trait: structured workflows.
Clear detection signals, evidence-based retraining triggers, high-quality data refresh pipelines, and controlled release processes separate teams that catch drift early from those that discover it through business impact.
Sama provides ML Professionals and AI team Leads with an indispensable solution for Computer Vision data labeling.
