SAM is a foundation model for segmentation. It has been trained on 11 million images, and over 1B masks. It is composed of 3 primary modules: an image encoder, a prompt encoder, and a mask decoder.


Benchmarking Meta’s latest Foundation Model on Realistic Annotation Use CasesRecently, Meta AI’s release of the Segment Anything Model (SAM) has sparked a lot of interest and excitement in the Computer Vision (CV) community. SAM is an image segmentation model that can provide segmentation masks for a variety of input prompts, and that demonstrates zero-shot transfer abilities across a wide range of tasks and datasets. Unquestionably, SAM has achieved impressive results, and strongly contributes to the era of foundation models for CV.Of course, no model is perfect - there are always limitations to consider. At Sama, we encounter difficult annotation use cases every day, and we deal with a lot of the edge cases that can cause Machine Learning (ML) systems to fail.The purpose of this article, the first in a series, is not only to test out SAM but also to investigate some broader questions: do foundation models perform well in all scenarios, especially when compared with more “traditional” models, and what are the caveats that need to be taken into account when using these models for ML-assisted annotation?To answer those questions, we conducted the following experiments:
SAM is a foundation model for segmentation. It has been trained on 11 million images, and over 1B masks. It is composed of 3 primary modules: an image encoder, a prompt encoder, and a mask decoder. A single image embedding is produced by the image encoder while different prompt encoding modules are specifically designed for efficient encoding of various prompt modes. Combining the image embedding with prompt encodings, a lightweight decoder is then able to generate segmentation masks with impressive speed and quality.The workflow described above can be well illustrated by this architecture diagram from SAM’s research paper:
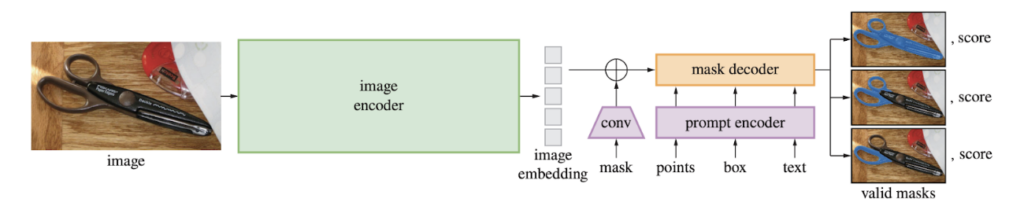
SAM architecture, as depicted by the authors in https://arxiv.org/abs/2304.02643This makes SAM great at general segmentation tasks, and we expect it to perform well on average on a variety of problems. However, when one looks at dataset-specific annotation instructions, SAM may not be able to grasp finer details as well as a dedicated, fine-tuned model, which is the main hypothesis we are putting forward here. For example, SAM might be not able to grasp dataset-specific details such as the absence (or presence) of holes in a given class of objects.We also hypothesize that another limitation of SAM could be its inability to capture small objects and boundary details. SAM uses a standard Transformer architecture for image encoding. Therefore, when it projects input images into a lower-resolution embedding space, very refined details might be lost in the process. Furthermore, SAM does not contain any added refinement modules or zoom-in functionality, and its training process focuses on coverage and generalization rather than granularity. All these factors can make SAM less suitable for high-accuracy scenarios.Based on our own experience, we know that it is hard for ML-assisted solutions to boost annotation efficiency in a significant way they come with near-pixel-perfect predictions, especially when a production-level accuracy is required, as manual editing is often more time-consuming than labeling from scratch for our expert annotators. Thus, this quality limitation can be an important deciding factor when evaluating SAM’s suitability for production deployment.In terms of performance, SAM’s inference speed is quite fast, as it can generate a segmentation result in 50 milliseconds for any prompt in the web browser with CPU. It’s worth noting that this number assumes that the image embedding is already precomputed. Encoding the image requires some extra computational resources and time. While this is not an obstacle, practitioners should keep this in mind when considering integrating SAM into their toolkit.
At Sama, we have designed a custom model to achieve high pixel accuracy in interactive segmentation for specific customer use cases. Our model differs from SAM in a few ways. First, instead of relying on loosely defined bounding boxes, our model takes extreme point clicks as input. These clicks correspond to the top, bottom, left-most, and right-most parts of the object to be segmented, as illustrated in the following figure:

Based on our experience, this input sends more valuable information and greatly helps boosting model performance. Additionally, we added a refinement module to it that further improves the boundary quality of the segmentation results. Our pipeline is therefore composed of a two-stage model with as little as 9M parameters and 40MB in size for each stage. With this size, the models can be trained on a single GPU of 16 GB, and the total inference time is less than one second on CPU.That being said, we wanted to compare our custom setup to SAM's bounding box approach, which is one of the go-to approaches that SAM suggests for interactive segmentation. To make a realistic comparison, we first provided SAM with a loose bounding box with 20% buffer to the box sidelength (hereinafter referred to as "SAM loose box"), which is one preferred usage pattern commonly observed according to our industry experience. We also launched experiments to probe SAM’s performance when provided with exact bounding boxes around the object (hereinafter referred to as "SAM tight box"). While we acknowledge that SAM is capable of leveraging other user prompts, we will focus our experiments on the simplest and most user-friendly setting, and will reserve experiments on more complex user interactions with SAM for further studies.To gain a quick sense of how SAM performs compared to our setup, we first conducted an experiment using the COCO dataset, as it contains a wide range of real-world images in many different contexts and with pixel-level annotations. The dataset was split into two disjoint sets (train and test). Our custom model was trained on the train set, and the exact same test dataset was used for both our model and SAM to ensure fair comparison.
After conducting our experiments and analysis, we observed that our custom model outperforms the other two regimes, i.e., SAM with loose and tight boxes. Our method achieved 0.863 in terms of mIOU score compared to 0.760 for SAM tight box and 0.657 for SAM loose box. The per-category results are presented in the following plot, which shows the mean IOU performance of each regime, with the x-axis indicating different categories from the COCO dataset:

It is clear that our custom model performs better across various categories. SAM with tight box shows significant improvement compared to its loose box counterpart, highlighting the importance of providing precise boxes when using SAM. However, the overall performance gap between SAM and our method suggests that customized modeling may still be necessary to capture things that SAM might have missed.After further analysis of the results, we've compiled some highlights for AI practitioners who are curious about our findings:Our experiments showed that user interaction patterns in the context of ML-assisted annotation can be critical to the success of the deployment. This can be one of the main causes of the performance gap between our model and SAM loose box. In the following figure, we observed that SAM loose box is confused and takes some background as foreground by mistake, while our model has no issue because it can leverage the extreme points to locate object boundaries.

Furthermore, even though SAM can undoubtedly be applied out-of-the-box as a tool for interactive segmentation in a general sense, it is important to note that SAM may not be perfect for high-accuracy regimes, as also acknowledged in the SAM paper. Throughout our experiments, we were impressed by the quality of SAM’s predictions considering the model has not been specifically trained on any of the target datasets. However, upon closer inspection, it is still possible to identify some cases where SAM’s predictions are not 100% perfect. Taking the leftmost case in the following figure as an example, if you zoom in and look specifically for the shoulder of the person and the segmentation result on the red t-shirt, SAM fails to classify some of the red pixels as foreground. Similar issues can be observed in the other three cases (e.g. missing part of leaves and shoes, and overshooting of the mask in the tennis racket example):
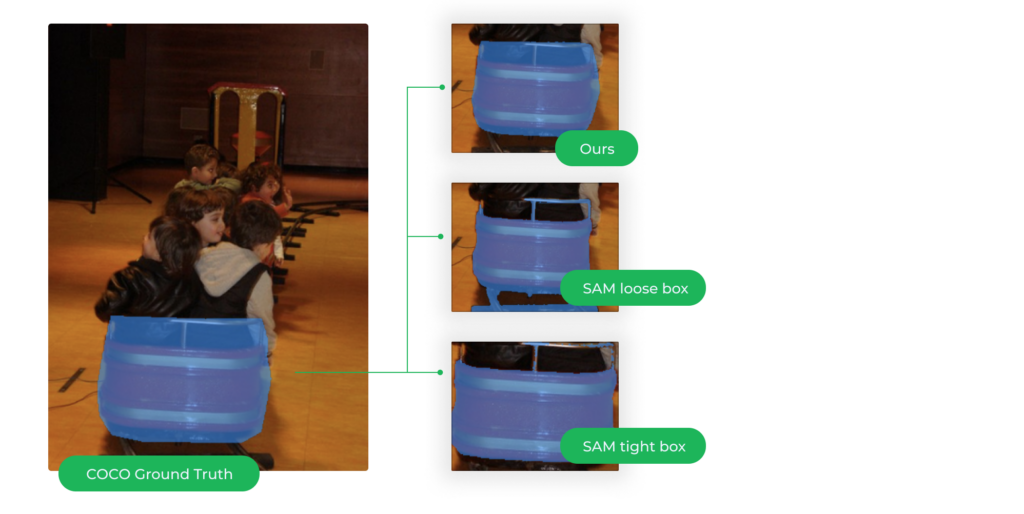
From the SAM paper, we would know that the model is projecting images into a lower resolution embedding space, and this can limit its ability to capture finer details. Therefore, while SAM’s predictions are generally accurate, they are not perfect and can require further edits or fixes in some cases.Another key observation is the importance of understanding the peculiarity of the dataset of interest. For example, we found that our customized model outperforms the SAM model in dealing with objects that reflect the peculiarities of COCO annotations. In the example illustrated in the following figure, the customized model was able to segment the whole object even though there is some hollow area. However, SAM seems to have a hard time deciding while dealing with this kind of dataset-specific peculiarities.
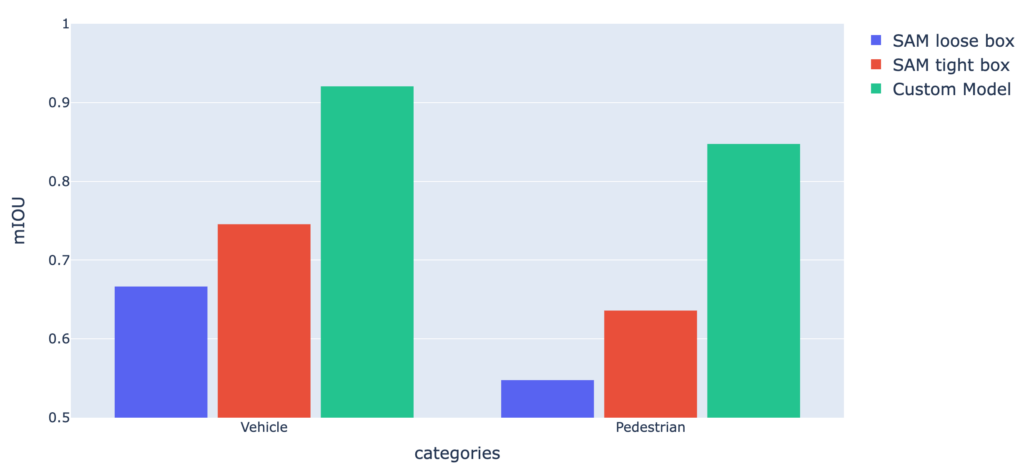
In order to gain a more comprehensive understanding of the model’s behaviour, we conducted a follow-up experiment on a customer annotation project that focuses on instance segmentation for urban scenes in the Automotive domain. We took around 40K images containing 220K segmented objects for training, and 10K images with 56K segmented objects for testing. The annotation instructions involve instance segmentation for two categories: vehicles and pedestrians. There are also specific labeling instructions for this project such as including holes as part of foreground and grouping multiple overlapping objects of the same category into a single object.The results of our experiment on this customer dataset are consistent with our observations from our COCO experiment: our model achieved a mIOU of 0.888 compared to 0.719 for SAM tight box and 0.637 for SAM loose box. While the performance of SAM tight box is competitive, our model is still better in terms of mIOU. Per-category mIOU results are presented in the following histogram:
Overall, the take-home messages are two-fold:
SAM has greatly stimulated research on foundation models in the computer vision community. However, as evidenced by the experiments in our research, there is still work to be done before foundation models can solve everything for us. In particular, when it comes to interactive ML-assisted annotation, our experiments suggest that there is still value in research work that aims to deliver higher-accuracy customized solutions with smarter user interaction patterns.As mentioned earlier, given the scope of this article, we only tested SAM’s basic bounding box setup without spending excessive resources and time. It is important to note that SAM’s capabilities could certainly surpass those observed in our experiments by either incorporating other prompt modes or testing it on other datasets. Additionally, there may be efficient methods allowing for fine-tuning SAM to achieve the last bit of accuracy improvement and customization. No matter what, while SAM can be a good out-of-the-box tool for interactive segmentation, it’s important to keep in mind its strengths and limitations when deciding what are the best approaches to take to solve your specific business challenges.On a final note, it’s worth emphasizing that when we are talking about annotation at scale, the interaction between AI tools and the end-users is critical to the success of any production workflow. This is a topic we are highly familiar with, based on our 15+ years of data annotation experience, with full-time annotators, ML engineers and UX designers working together on customer projects within the same company. First of all, incorrect or inconsistent predictions can decrease user trust. Furthermore, even with highly precise AI predictions, suboptimal UX patterns can still greatly hinder the adoption of ML-assisted annotation. Hence, we should focus not only on the accuracy of AI systems but also on the development of effective user interaction patterns, and this is the only way towards fully leveraging the power of ML-assisted solutions into real-world applications.Learn more about how Sama can annotate data for computer vision use cases with high accuracy while meeting the challenges of scale.
Lorem ipsum dolot amet sit connsectitur
Sama provides ML Professionals and AI team Leads with an indispensable solution for Computer Vision data labeling.
